Vast amounts of useful data are stored and processed in ad hoc formats. Traditional databases and Xml systems provide rich infrastructure for processing well-behaved data, but are of little help when dealing with ad hoc formats. Examples that we face at AT&T include call detail data [CFP+04], web server logs [KR01], netflows capturing internet traffic [net], log files characterizing IP backbone resource utilization, wire formats for legacy telecommunication billing systems, etc. Such data may simply require processing before it can be loaded into a data management system, or it may be too large or too transient to make such loading cost effective.
Processing ad hoc data can be challenging for a variety of reasons. First, ad hoc data typically arrives “as is”: the analysts who receive it can only say “thank you,” not request a more convenient format. Second, documentation for the format may not exist at all, or it may be out of date. A common phenomenon is for a field in a data source to fall into disuse. After a while, a new piece of information becomes interesting, but compatibility issues prevent data suppliers from modifying the shape of their data, so instead they hijack the unused field, often failing to update the documentation in the process.
Third, such data frequently contain errors, for a variety of reasons: malfunctioning equipment, race conditions on log entry [KR01], non-standard values to indicate “no data available,” human error in entering data, unexpected data values, etc. The appropriate response to such errors depends on the application. Some applications require the data to be error free: if an error is detected, processing needs to stop immediately and a human must be alerted. Other applications can repair the data, while still others can simply discard erroneous or unexpected values. For some applications, errors in the data can be the most interesting part because they can signal where two systems are failing to communicate.
A fourth challenge is that ad hoc data sources can be high volume: AT&T’s call-detail stream contains roughly 300 million calls per day requiring approximately 7GBs of storage space. Although this data is eventually archived in a database, analysts mine it profitably before such archiving [CP98, CP99]. More challenging, the Altair project at AT&T accumulates billing data at a rate of 250-300GB/day, with occasional spurts of 750GBs/day. Netflow data arrives from Cisco routers at rates over a gigabyte per second [CGJ+02]! Such volumes mean it must be possible to process the data without loading it all into memory at once.
Finally, before anything can be done with an ad hoc data source, someone has to produce a suitable parser for it. Today, people tend to use C or Perl for this task. Unfortunately, writing parsers this way is tedious and error-prone, complicated by the lack of documentation, convoluted encodings designed to save space, the need to produce efficient code, and the need to handle errors robustly to avoid corrupting down-stream data. Moreover, the parser writers’ hard-won understanding of the data ends up embedded in parsing code, making long-term maintenance difficult for the original writers and sharing the knowledge with others nearly impossible.
The Pads system makes life easier for data analysts by addressing each of these concerns. It provides a declarative data description language that permits analysts to describe the physical layout of their data, as it is. The language also permits analysts to describe expected semantic properties of their data so that deviations can be flagged as errors. The intent is to allow analysts to capture in a Pads description all that they know about a given data source and to provide the analysts with a library of useful routines in exchange.
Pads descriptions are concise enough to serve as documentation and flexible enough to describe most of the data formats we have seen in practice, including ASCII, binary, Cobol, and mixed data formats. The fact that useful software artifacts are generated from the descriptions provides strong incentive for keeping the descriptions current, allowing them to serve as living documentation.
Given a Pads description, the Pads compiler produces customizable C libraries and tools for parsing, manipulating, and summarizing the data. The core C library includes functions for reading the data, writing it back out in its original form, and accumulating statistical properties. Future releases will include support for pretty printing the data, writing it into a canonical Xml form, and implementing the Galax data model, which allows user to query Pads data using XQuery.
The declarative nature of Pads descriptions facilitates the insertion of error handling code. The generated parsing code checks all possible error cases: system errors related to the input file, buffer, or socket; syntax errors related to deviations in the physical format; and semantic errors in which the data violates user constraints. Because these checks appear only in generated code, they do not clutter the high-level declarative description of the data source. The result of a parse is a pair consisting of a canonical in-memory representation of the data and a parse descriptor. The parse descriptor precisely characterizes both the syntactic and the semantic errors that occurred during parsing. This structure allows analysts to choose how to respond to errors in application-specific ways.
With such huge datasets, performance is critical. The Pads system addresses performance in a number of ways. First, we compile the Pads description rather than simply interpret it to reduce run-time overhead. Second, the generated parser provides multiple entry points, so the data consumer can choose the appropriate level of granularity for reading the data into memory to accommodate very large data sources. Finally, we parameterize library functions by masks, which allow data analysts to choose which semantic conditions to check at run-time, permitting them to specify all known properties in the source description without forcing all users of that description to pay the run-time cost of checking them.
Given the importance of the problem, it is perhaps surprising that more tools do not exist to solve it. Xml and relational databases only help with data already in well-behaved formats. Lex and Yacc are both over- and under- kill. Overkill because the division into a lexer and a context free grammar is not necessary for many ad hoc data sources, and under-kill in that such systems require the user to build in-memory representations manually, support only ASCII sources, and don’t provide extra tools. ASN.1 [Dub01] and related systems [asd] allow the user to specify an in-memory representation and generate an on-disk format, but this doesn’t help when given a particular on-disk format. Existing ad hoc description languages [Bac02, MC98, erla] are steps in the right direction, but they focus on binary, error-free data and they do not provide auxiliary tools.
A Pads description specifies the physical layout and semantic properties of an ad hoc data source. The language provides a type-based model: basic types describe atomic data such as integers, strings, dates, etc., while structured types describe compound data built from simpler pieces.
The Pads library provides a collection of broadly useful base types. Examples include 8-bit unsigned integers (Puint8), 32-bit integers (Pint32), dates (Pdate), strings (Pstring), and IP addresses (Pip). Semantic conditions for such base types include checking that the resulting number fits in the indicated space, i.e., 16-bits for Pint16. By themselves, these base types do not provide sufficient information to allow parsing because they do not specify how the data is coded, i.e., in ASCII, EBCDIC, or binary. To resolve this ambiguity, Pads uses the ambient coding, which the programmer can set. By default, Pads uses ASCII. To specify a particular coding, the description writer can select base types which indicate the coding to use. Examples of such types include ASCII 32-bit integers (Pa_int32), binary bytes (Pb_int8), and EBCDIC characters (Pe_char). In addition to these types, users can define their own base types to specify more specialized forms of atomic data.
To describe more complex data, Pads provides a collection of structured types loosely based on C’s type structure. In particular, Pads has Pstructs, Punions, and Parrays to describe record-like structures, alternatives, and sequences, respectively. Penums describe a fixed collection of literals, while Popts provide convenient syntax for optional data. Each of these types can have an associated predicate that indicates whether a value calculated from the physical specification is indeed a legal value for the type. For example, a predicate might require that two fields of a Pstruct are related or that the elements of a sequence are in increasing order. Programmers can specify such predicates using Pads expressions and functions, written using a C-like syntax. Finally, Pads Ptypedefs can be used to define new types that add further constraints to existing types.
Pads types can be parameterized by values. This mechanism serves both to reduce the number of base types and to permit the format and properties of later portions of the data to depend upon earlier portions. For example, the base type Puint16_FW(:3:) specifies an unsigned two byte integer physically represented by exactly three characters, while the type Pstring(:’ ’:) describes a string terminated by a space. Parameters can be used with compound types to specify the size of an array or which branch of a union should be taken.
As an example, consider the common log format for Web server logs. A typical record looks like the following:
207.136.97.49 - - [15/Oct/1997:18:46:51 -0700] "GET /tk/p.txt HTTP/1.0" 200 30
recording the IP address of the requester; either a dash or the owner of the TCP session; either a dash or the login of the requester; the date; the actual request, which consists of the HTTP method, the requested URL, the HTTP version number; a response code; and the number of bytes returned. A Pads type describing the request portion is
Pstruct http_request_t {
’\"’; http_method_t meth; /- Method used during request
’ ’; Pstring(:’ ’:) req_uri; /- Requested uri.
’ ’; http_v_t version : checkVersion(version, meth);
/- HTTP version
’\"’;
};
This Pstruct uses (omitted) auxiliary types http_method_t and http_v_t to describe the HTTP method and version formats, respectively. It uses character literals ("\"" and ’ ’) to consume the quotes and spaces from the physical representation. The version field has a constraint predicate checkVersion which ensures that obsolete HTTP methods LINK and UNLINK are only used with HTTP version 1.0.
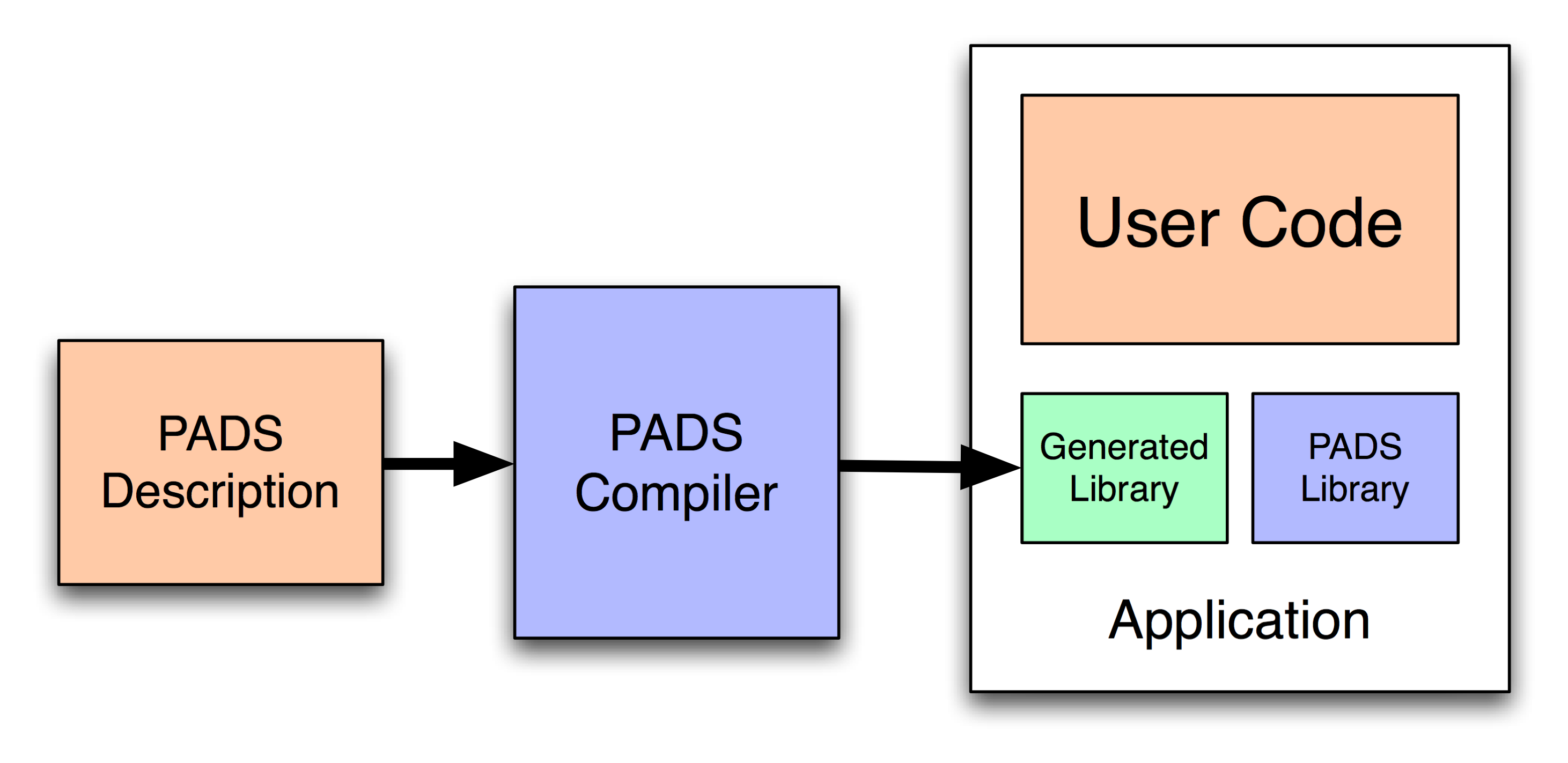
From a description, the Pads compiler generates a C library for parsing and manipulating the associated data source. Figure 1.1 shows the architecture of the Pads system. The output of the Pads compiler is linked with the Pads standard library and user code to form an executable. In addition to the generated library, the Pads system provides template programs for accumulating, pretty-printing, and converting into Xml data formats that have a particular format, namely, an optional header followed by a sequence of records.
From each type in a Pads description, the compiler generates
The C declarations for the in-memory representation, the mask, and the parse descriptor all share the structure of the Pads type declaration. The mapping to C for each is straightforward: Pstructs map to C structs with appropriately mapped fields, Punions map to tagged unions coded as C structs with a tag field and an embedded union, Parrays map to a C struct with a length field and a pointer to a dynamically allocated sequence, Penums map to C enumerations, Poptions to tagged unions, and Ptypedefs to C typedefs. Masks include auxiliary fields to control behavior at the level of a structured type, and parse descriptors include extra fields to record the state of the parse, the number of detected errors, the error code of the first detected error, and the location of that error.
The parser takes a mask as an argument and returns an in-memory representation and a parse descriptor. The mask allows the user to specify which constraints the parser should check and which portions of the in-memory representation it should fill in. This control allows the description-writer to specify all known constraints about the data without worrying about the run-time cost of verifying potentially expensive constraints for time-critical applications.
Appropriate error-handling can be as important as processing error-free data. The parse descriptor marks which portions of the data contain errors and characterizes the detected errors. Depending upon the nature of the errors and the desired application, programmers can take the appropriate action: halting the program, discarding parts of the data, or repairing the errors. If the mask requests that a data item be verified and set, and if the parse descriptor indicates no error, then the in-memory representation satisfies the semantic constraints on the data.
Because we generate a parsing function for each type in a Pads description, we support multiple-entry point parsing, which allows us to accommodate larger-scale data. For a small file, programmers can define a Pads type that describes the entire file and use that type’s parsing function to read the whole file with one call. For larger-scale data, programmers can sequence calls to parsing functions that read manageable portions of the file, e.g., reading a record at a time in a loop. The parsing code generated for Parrays allows users to choose between reading the entire array at once or reading it one element at a time, again to support parsing and processing very large data sources.
The ratio of the size of the data description to the size of the generated code gives a rough measure of the leverage of the declarative description. For the 68 line Sirius data description, the compiler yields a 1432 line .h file and a 6471 line .c file. This expansion comes from the extensive error checking in the generated parser and the number of generated utility functions.
There are many tools for describing data formats. For example, ASN.1 [Dub01] and ASDL [asd] are both systems for declaratively describing data and then generating libraries for manipulating that data. In contrast to Pads, however, both these systems specify the logical representation and automatically generate a physical representation. Although useful for many purposes, this technology does not help process data that arrives in predetermined, ad hoc formats.
More closely related work allows declarative descriptions of physical data [MC98, erlb, Bac02], motivated by parsing TCP/IP packets and Java jar-files. In contrast to our work, these systems only handle binary data and assume the data is error-free or halt parsing if an error is detected.
We use the term external to refer to the physical data characterized by a Pads description. Such data might come from disk or over-the-wire for network applications.
In describing the syntax of various Pads expressions, we will use a BNF grammar. The syntax for pervasive features of the languages appears in Chapter 3. The syntax of a particular feature appears in the chapter describing that feature. We adopt the following conventions:
In Chapter 2, we describe a sample use of the Pads system. It provides an overview of the data description language and illustrates the use of the generated library. Chapter 3 describes features of the Pads language common to all Pads types. Successive chapters assume familiarity with the material in this chapter. Chapter 4 describes built-in Pads base types, while Chapters 5 through 10 describe the structured types that Pads provides. These chapters describe the syntax and semantics of the Pads language and the core of the library generated for each such type declaration. In Chapter 14, we document how to use the Pads library, and in Chapter 15 we explain the various ways in which the Pads library can be customized. Chapter 16 describes the generated accumulator library.
Source code for Pads is available for download with a non-commercial use license from:
The Pads distribution contains:
This section describes how to use the Pads compiler padsc. The simplest use of padsc is to compile a Pads source file to a C header and implementation file. The command
padsc my.p
will produce my.h and my.c files containing the generated library. By default, the compiler will also generate a file my.xsd containing the XSchema for the Pads canonical embedding of the data source into Xml.
If the directory containing my.p has a subdirectory named gen, then the compiler will put the generated files in that subdirectory. Otherwise, it will put them in the same directory as the my.p file.
padsc [-wnone] [-xsnone] [-anone] [-x] [-hist] [-cluster] [-r <string>] [-b <string>] [-I <string> ...] [-D <string> ...] [-U <string> ...] [-t] [--help] file... -wnone suppress write function generation -xsnone suppress XSchema generation -anone suppress accumulator generation -x output Galax Data API -hist output histogram functions -cluster output cluster functions -r output directory -b add base type table -I augment include path -D add definition -U remove definition -t trace system commands File extensions: .p PADS files
Figure 1.2: Command-line switches understood by the Pads compiler.
Figure 1.2 lists the command-line options supported by the Pads compiler.
Pads uses the Sfio library for managing I/O streams. Sfio provides functionality similar to that of Stdio, the ANSI C Standard I/O library, but via a distinct interface. Sfio provides both source and binary Stdio emulation packages. Sfio is included in the Pads distribution. More information about Sfio is available from www.research.att.com/gsf/download/ref/sfio/sfio.html .
Please report any bugs in the Pads implementation or problems with this manual by electronic mail to pads-dev@research.att.com.